Nos últimos anos, governos, organizações internacionais, acadêmicos, sociedade civil e empresas têm elaborado inúmeros princípios para a Inteligência Artificial (IA) com o objetivo de alinhar o desenvolvimento dessa tecnologia com o bem-estar, a ética e a sustentabilidade.
Apesar de mais de cento e sessenta propostas existirem para desenvolver a IA de forma “ética” ou “responsável”, há pouco trabalho dedicado a analisar criticamente esses princípios e sua viabilidade para orientar o avanço tecnológico.
Em outras palavras, os princípios éticos da IA se transformaram em crenças tecnológicas que nos prometem progresso, bem-estar e um futuro melhor. Em tempo, sem questionar o que significa progresso, bem-estar para quem e a que custo, nem se há consenso sobre o que seja “um futuro melhor”.
Esses princípios, como resultado, tendem a fortalecer narrativas tecnológicas que pressupõem a universalidade de valores, visões de mundo e do futuro. Além disso, alimentam a ideia de que a tecnologia (especialmente a IA) é neutra e objetiva, podendo atuar como um grande equalizador no mundo.
Mas será possível afirmar que a tecnologia é neutra? Ou será que a própria técnica codifica valores durante o seu desenvolvimento? E, se assim for, quais são esses valores e para onde eles orientam o desenvolvimento tecnológico?
Não deveria nos surpreender que a resposta às perguntas anteriores seja que, longe de ser neutra e objetiva, a IA reforça estruturas de poder dominantes, em particular o capitalismo, o colonialismo e o patriarcado. Mais preocupante ainda, em vez de funcionar como o “grande equalizador”, a IA está ampliando a lacuna digital global, concentrando o poder em um punhado de atores no setor privado (as gigantes de tecnologia) e no Norte Global.
Portanto, é de extrema importância que, do Sul, questionemos até que ponto é possível direcionar esse fenômeno tecnológico, para onde ele está indo e se existem caminhos que nos permitam avançar em direção a outros paradigmas tecnológicos alinhados com nossas visões e interesses.
A boa notícia é que outros futuros tecnológicos são possíveis! No entanto, antes de apresentar alternativas, é importante compreender como chegamos até aqui. Como as estruturas de poder no campo da IA foram consolidadas por meio da estreita relação entre técnica e prática?
Não deveria nos surpreender que a resposta às perguntas anteriores seja que, longe de ser neutra e objetiva, a IA reforça estruturas de poder dominantes, em particular o capitalismo, o colonialismo e o patriarcado.
A caixa preta
A IA pode ser criada por meio de várias arquiteturas. A mais amplamente utilizada atualmente é chamada de aprendizado de máquina (machine learning). Esse tipo de sistema aprende a emular comportamentos com base em exemplos desse comportamento que são apresentados ao sistema na forma de dados.
Portanto, se quisermos criar um sistema de IA que classifique imagens de animais por espécie, devemos mostrar várias imagens de exemplares de cada uma das espécies. O sistema pode criar um modelo de classificação usando os dados apresentados durante a fase de aprendizado, também conhecida como fase de treinamento.
Os dados utilizados durante a fase de treinamento se tornam a realidade que o sistema vai reproduzir. Se os dados refletirem, por exemplo, desigualdade ou discriminação (como a de gênero), é muito provável que esses padrões sejam aprendidos e reproduzidos pelo sistema (o que ocorre com frequência). O aprendizado de máquina, longe de ser neutro ou objetivo, é projetado para reproduzir padrões.
Isso ocorre porque esses sistemas são construídos usando estatísticas e baseiam-se em encontrar padrões e relações entre os dados. Esse enfoque, embora produza resultados impressionantes, como o Chat-GPT, tem o defeito de gerar previsões cuja lógica precisa não podemos entender. É por isso que os sistemas de aprendizado de máquina também são chamados de “caixas pretas”.
Embora não possamos entender como ou por que um modelo de aprendizado de máquina fez uma determinada previsão, podemos avaliar quão bom ele é em emular o comportamento desejado. Para avaliá-lo, são apresentados dados que ele nunca viu antes (dados de avaliação) e a qualidade de suas previsões é estudada. A forma mais comum de avaliar o desempenho de um sistema é chamada de “precisão”.
De maneira geral, podemos pensar na precisão como a porcentagem de previsões corretas feitas por um sistema dividida por cem. Se avaliarmos nosso sistema de classificação de animais por espécie com um conjunto de 100 imagens e ele classificar corretamente 80 delas, a porcentagem de previsões corretas é de 80% e a precisão é 0,8.
Dado que o aumento na precisão está relacionado ao aumento na porcentagem de previsões corretas, uma grande quantidade de trabalho em IA tem se concentrado em otimizar essa métrica sob a premissa de que maior precisão equivale a maior progresso no campo. Mas será realmente assim?
A questão do poder de computação
Mais do que uma quantidade ou uma porcentagem, podemos considerar a precisão como uma forma de codificar o que é considerado importante para o desenvolvimento da IA e como essa importância é medida. Essa métrica representa uma valoração.
Mas o que essa valoração favorece? Quais são os impactos dessa métrica no desenvolvimento tecnológico? É possível direcionar a tecnologia por meio de valorações diferentes? Para explorar essas perguntas, é importante compreender o desenvolvimento histórico da IA nas últimas duas décadas.
Atualmente, existem três fatores-chave que impulsionam o avanço da IA: inovação em algoritmos, dados e a quantidade de poder de computação utilizada no treinamento dos sistemas. Esse último fator corresponde ao número de cálculos ou operações matemáticas realizadas para criar os modelos.
Em particular, o poder de computação é o melhor indicador de precisão, pois o treinamento de sistemas de aprendizado de máquina depende da otimização dos valores dos parâmetros (ou variáveis) nos quais o modelo se baseia.
Em outras palavras, aumentar a precisão dos sistemas, especialmente no aprendizado de máquina, requer um aumento no poder de computação usado para treiná-los, pois isso permite encontrar mais relações e padrões nos dados (codificados nos parâmetros).
Essa relação entre o número de parâmetros e a precisão dos sistemas levou a um aumento constante na complexidade dos modelos, que agora dependem de um número cada vez maior de parâmetros. Para se ter uma ideia da velocidade dessas mudanças, o ELMo (um dos maiores modelos de processamento de linguagem natural), desenvolvido em 2018, tinha 94 milhões de parâmetros; o GPT-3 (o modelo usado como base para o Chat-GPT), produzido em 2020, depende de 175 bilhões; enquanto o GPT-4 (a nova versão do GPT-3), produzido em 2023, possui mais de um trilhão de parâmetros.
Para compreender o estado atual do campo de IA e refletir sobre seus possíveis futuros, é fundamental analisar os requisitos computacionais dos sistemas e os impactos que esses requisitos tiveram em diferentes atores e regiões do mundo.
Por mais de seis décadas, de 1950 a 2011, a quantidade de poder de computação usada para desenvolver sistemas de IA seguia um padrão semelhante à Lei de Moore, duplicando-se a cada dois anos. Durante esse período, diversos grupos de pesquisa usavam o mesmo tipo de software e hardware, e os computadores tinham propósitos gerais.
No entanto, o ano de 2012 marcou o início de uma nova era no desenvolvimento de IA. A partir desse momento, a taxa de uso de poder de computação para treinar modelos de IA começou a dobrar a cada 3,4 meses.
Essa mudança drástica no uso de poder de computação está relacionada à introdução de hardware especializado para processamento, em particular o uso das Unidades de Processamento Gráfico (GPU). As GPUs já existiam antes de 2012, mas eram usadas principalmente para jogos e animações gráficas. Após 2012, o hardware especializado se tornou fundamental para o desenvolvimento de IA.
Atualmente, grandes empresas de tecnologia como Amazon, Apple, Google e Tesla trabalham no design de hardware especializado. Em muitos casos, esse hardware, como as Unidades de Processamento Tensorial (TPU) criadas pelo Google, é de uso exclusivo das empresas que o desenvolvem ou está acessível a desenvolvedores externos apenas por meio de serviços de nuvem (Google Cloud). Isso tem consequências negativas, como o aumento da dependência em relação às grandes empresas de tecnologia para o desenvolvimento de IA.
Além disso, embora esses equipamentos possam ser alugados, os custos para criar modelos de IA de última geração (estado da arte) são extremamente altos, tornando-os totalmente inacessíveis para a maioria dos grupos de pesquisa. Em 2021, os custos dos grandes modelos estavam muito abaixo de um milhão de dólares (com exceções), enquanto em 2022 já ultrapassavam essa marca.
O desenvolvimento de hardware especializado e outras infraestruturas digitais tem contribuído para a criação de um oligopólio que controla a maior parte dos recursos computacionais necessários para criar sistemas de IA de alto desempenho.
Em outras palavras, o aumento na quantidade de poder de computação necessária para criar sistemas de IA influenciou significativamente o desenvolvimento do campo, favorecendo apenas um pequeno grupo de atores.
Uma das mudanças mais significativas no desenvolvimento da IA nesta nova era, pós-Lei de Moore e pós-2012, é que os grupos de pesquisa deixaram de estar em situações comparáveis. Isso ocorre porque, nesse campo, o acesso ao poder de computação está fortemente ligado à produção de resultados de alto nível, de modo que os grupos sem acesso a hardware especializado – e sem a capacidade de criar o software necessário para implementá-lo – estão em desvantagem.
Em outras palavras, a partir de 2012, uma lacuna de poder computacional se abriu, levando à centralização da produção de conhecimento sobre IA em um pequeno grupo de atores (muitos deles grandes empresas de tecnologia), desdemocratizando o campo.
Além disso, essas mudanças fizeram com que os grupos que atualmente produzem os melhores sistemas de IA (com base em precisão ou métricas relacionadas) o façam por meio do uso de quantidades massivas de poder de computação, o que essencialmente significa que estão comprando melhores resultados.
O Impacto no Sul Global
Este novo paradigma tecnológico não afetou todas as regiões do mundo da mesma forma. Na verdade, favoreceu o Norte Global e limitou o desenvolvimento tecnológico em várias regiões do Sul. O Gráfico abaixo mostra a porcentagem de publicações (revisadas por pares) produzidas em várias regiões em todo o mundo.
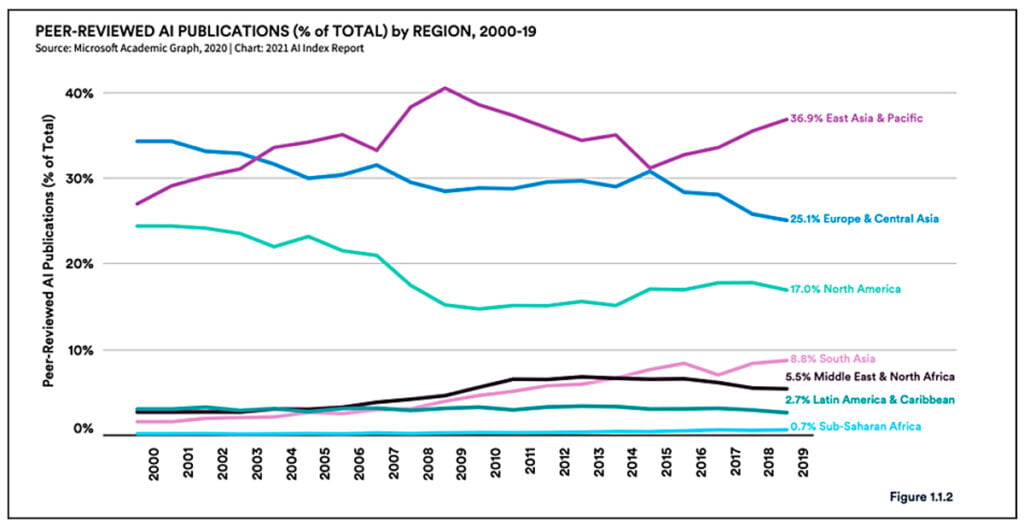
O percentual de representação da América Latina e do Caribe no campo tem diminuído, ainda que marginalmente, de forma constante desde 2012. Complementarmente, nas últimas duas décadas, a participação de empresas de tecnologia (como Google e Facebook) nas principais conferências de IA aumentou. Atualmente, essas empresas representam cerca de 30% dos trabalhos nesses espaços.
A criação de sistemas de IA envolve custos econômicos e ambientais significativos. Hoje em dia, o treinamento de um sistema de IA de última geração requer milhões de dólares. Portanto, o desenvolvimento desse tipo de tecnologia está fora do alcance da maioria dos grupos de pesquisa, especialmente aqueles no Sul Global.
Além disso, a enorme quantidade de poder de computação necessária para criar esses sistemas resulta em emissões de gases de efeito estufa comparáveis às emissões combinadas de cinco automóveis ao longo de toda a sua vida útil, incluindo a fabricação.
A busca por melhorar o desempenho da IA teve consequências significativas no desenvolvimento do campo em nível global, principalmente o aumento dos custos e impactos ambientais associados ao desenvolvimento desses sistemas, bem como o agravamento da desigualdade. Diante disso, surge a pergunta: o que ganhamos com esse enfoque de desenvolvimento? Será que existem outros caminhos possíveis?
Repensando a Precisão na Inteligência Artificial
Embora a precisão meça o quão bons são os sistemas em prever comportamentos, os aumentos nessa métrica não tornam necessariamente essa tecnologia mais inteligente. Isso é relevante porque, atualmente, grande parte da pesquisa em IA está focada em projetar sistemas com melhor desempenho (ou seja, maior precisão) em testes específicos e em criar novos testes uma vez que os existentes tenham sido superados.
No entanto, há pouca clareza sobre se essa abordagem realmente cria sistemas mais inteligentes ou se, na realidade, os resultados dependem de enormes quantidades de poder de computação e dados (ou seja, estatísticas).
Por esses motivos, alguns especialistas, incluindo Timnit Gebru, defendem uma mudança nos objetivos de pesquisa que guiam a IA e propõem deixar de priorizar o design de sistemas que melhorem o desempenho em testes específicos. Em vez disso, eles enfatizam a pesquisa que ajude a entender como as máquinas superam esses testes.
Em resumo, propõe-se redirecionar as linhas de pesquisa em IA para aprimorar a compreensão de como os sistemas operam, em vez de continuar a produzir sistemas mais precisos cujo funcionamento não entendemos completamente.
Seria interessante considerar se é possível desenvolver estratégias que, de forma conjunta, possam ajudar a mitigar outros problemas decorrentes da excessiva ênfase dada à precisão no campo da IA, como o aumento da desigualdade e dos impactos ambientais. Felizmente, o trabalho sobre IA e mudança climática poderia servir como apoio para propor alternativas.
Em particular, estudos recentes identificaram a eficiência como uma métrica mais adequada do que a precisão para avaliar os sistemas de IA. Isso ocorre porque a eficiência significa relatar a quantidade de trabalho necessária para produzir um resultado de IA. Isso inclui quantificar o trabalho necessário para treinar o modelo e, quando aplicável, o trabalho usado em todos os experimentos de calibração (ajuste de hiper parâmetros).
Algumas das vantagens da eficiência sobre a precisão, incluem a capacidade de quantificar os impactos ambientais e promover melhorias na gestão de recursos, em vez de favorecer o uso de maiores quantidades de poder computacional. Nesse sentido, a eficiência permite realizar comparações mais justas entre sistemas, levando em consideração a quantidade de recursos usados para criar os modelos.
Definir o que entendemos por eficiência não é uma tarefa simples. Se queremos que essa métrica sirva para comparar sistemas, ela deve ser independente do laboratório, do tempo e do hardware utilizado. Encontrar uma maneira de atender a esses requisitos simultaneamente não é fácil.
Por exemplo, seria uma boa ideia definir a eficiência de um sistema de IA considerando a quantidade de emissões de carbono geradas durante seu desenvolvimento. No entanto, o problema com essa proposta é que as emissões geradas por sistemas de IA dependem das emissões da rede elétrica. Já estas, variam substancialmente de acordo com a localização e os tipos de energia (elétrica, eólica, hidrelétrica, etc.). Portanto, as emissões de carbono produzidas por um sistema de IA dependem do local onde ele foi desenvolvido.
Dado essa dependência entre localização e impactos ambientais, poderia ser proposto medir a eficiência levando em consideração a quantidade de eletricidade usada para criar cada modelo, em vez das emissões de carbono. Essa proposta tem a vantagem de ser independente tanto do tempo quanto da localização. Além disso, a maioria das GPUs (unidades de processamento gráfico) relata a quantidade de eletricidade que consome, facilitando o cálculo da quantidade de eletricidade necessária para gerar cada modelo de IA.
No entanto, essa métrica tem uma desvantagem: o consumo de energia usado para criar um modelo depende do hardware que foi utilizado. Portanto, usar a quantidade de energia necessária para criar o sistema como métrica independe do tempo e da localização, mas não é independente do equipamento. Isso significa que encontrar novas métricas que permitam comparações mais justas entre sistemas e que levem em consideração os impactos ambientais gerados por essa tecnologia, não é uma tarefa simples.
Essas valorações precisarão considerar que os sistemas de IA são produzidos em várias localidades, que variam em termos de equipamento e infraestrutura, afetando a capacidade de computação e os impactos ambientais resultantes de cada desenvolvimento tecnológico.
Definir novas valorações que possibilitem orientar o desenvolvimento da IA em direção a uma maior equidade e sustentabilidade dependerá de uma reflexão profunda sobre o que queremos priorizar e qual seria a melhor maneira de fazê-lo. Como vimos, esse processo deve ser acompanhado por uma compreensão das relações de poder e de como essas permeiam tanto a técnica quanto a prática.
Nessas conversas, as perspectivas do Sul Global têm muito a contribuir. Projetar estratégias para guiar essa tecnologia em direção a novos horizontes requer a conceitualização de intervenções que permitam redirecionar os vários processos envolvidos no desenvolvimento tecnológico, levando em consideração como esses se relacionam com experiências e contextos específicos.
A mudança não será fácil, mas uma coisa é clara: outros caminhos são possíveis. Construí-los dependerá de nossa capacidade de criar estratégias conjuntas que nos permitam caminhar em direção a eles.
Sofía Trejo é doutora em Matemática e atualmente atua como Learning Community Fellow no Instituto de Ética da Inteligência Artificial de Montreal (MAIEI). Seu trabalho de pesquisa se concentra em examinar os preconceitos algorítmicos e o papel da inteligência artificial na sociedade. Ela investiga como os algoritmos podem ser tendenciosos e como a IA impacta diversos aspectos da vida social.
Este texto foi publicado na Revista argentina Anfibia. Tradução nossa.